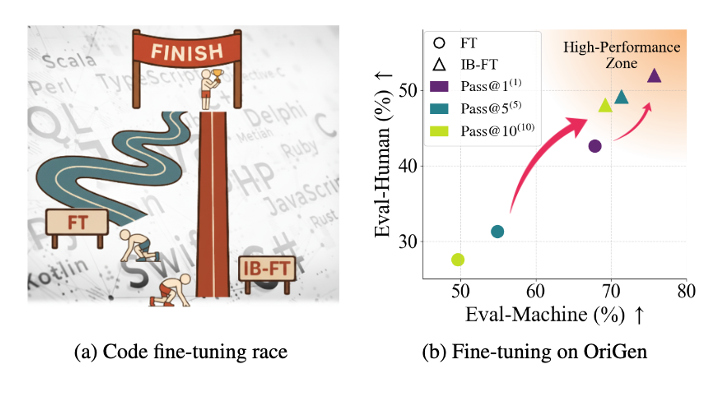
Adapting pretrained large language models (LLMs) to code domains via supervised fine-tuning (FT) has been commonly used for code generation. However, we identify a previously underappreciated failure mode, the \emphmemorization barrier, where strong memorization of downstream code data in the base model could trap optimization and prevent the standard FT from effectively acquiring new, generalizable code knowledge. To overcome this barrier, we propose the \emphinformation bottleneck (IB)-guided fine-tuning, termed IB-FT, which applies an IB penalty on hidden representations of the code data to compress spurious, memorized features while preserving task-relevant information. Extensive experiments on two code benchmarks (OriGen and Evol-CodeAlpaca-V1) show that IB-FT substantially alleviates the memorization barrier, improves top-1 performance (Pass@1), and yields far more stable gains under the stricter multi-sample metric \textPass@k^(m) (a problem counts as solved only if at least m of k samples pass unit tests) compared with conventional FT.
@inproceedings{wang2025reasoning,title={Breaking Memorization Barriers in LLM Code Fine-Tuning via Information Bottleneck for Improved Generalization},author={Wang, Changsheng and Xin, Chen and Liu, Sijia and Ke, Ding},year={2025}}
CCS AISec’25
LLM Unlearning on Noisy Forget Sets: A Study of Incomplete, Rewritten, and Watermarked Data
Changsheng Wang, Yihua Zhang, Dennis Wei, Jinghan Jia, Pin-Yu Chen, and Sijia Liu
In 18 th ACM Workshop on Artificial Intelligence and Security 2025
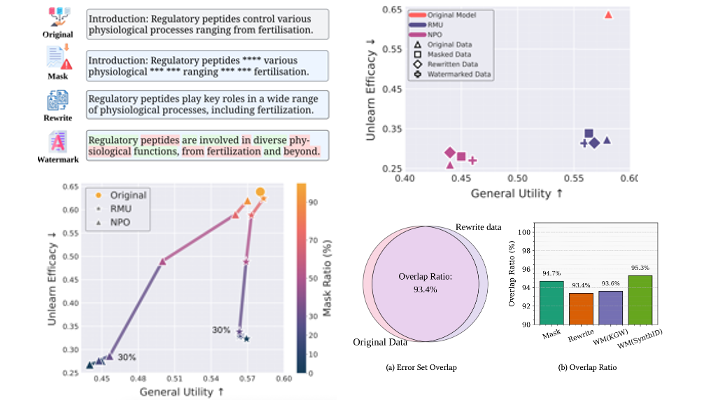
Large language models (LLMs) exhibit remarkable generative capabilities but raise ethical and security concerns by memorizing sensitive data, reinforcing biases, and producing harmful content. These risks have spurred interest in LLM unlearning, the task of removing knowledge associated with undesirable data from pre-trained models. However, most existing methods assume access to clean, well-defined forget data samples, whereas real-world forget data could often be low-quality, synthetically rewritten, or watermarked, casting doubt on the reliability of unlearning. This work presents the first study of unlearning under perturbed or low-fidelity forget data, referred to as noisy forget sets. By systematically benchmarking state-of-the-art LLM unlearning methods, RMU and NPO, on such noisy forget sets, we find that unlearning remains surprisingly robust to perturbations, provided that core semantic signals are preserved. To explain this robustness, we propose a saliency-based interpretation: key semantic components that drive forgetting remain consistently influential despite substantial variation in surface form. This suggests that unlearning algorithms are primarily guided by deep semantic cues rather than shallow lexical patterns.
@inproceedings{wang2025reasoninh,title={LLM Unlearning on Noisy Forget Sets: A Study of Incomplete, Rewritten, and Watermarked Data},author={Wang, Changsheng and Zhang, Yihua and Wei, Dennis and Jia, Jinghan and Chen, Pin-Yu and Liu, Sijia},booktitle={18 th ACM Workshop on Artificial Intelligence and Security},year={2025}}
EMNLP’25
Reasoning Model Unlearning: Forgetting Traces, Not Just Answers, While Preserving Reasoning Skills
Changsheng Wang*, Chongyu Fan*, Yihua Zhang, Jinghan Jia, Dennis Wei, Parikshit Ram, Nathalie Baracaldo, and Sijia Liu
In The 2025 Conference on Empirical Methods in Natural Language Processing 2025
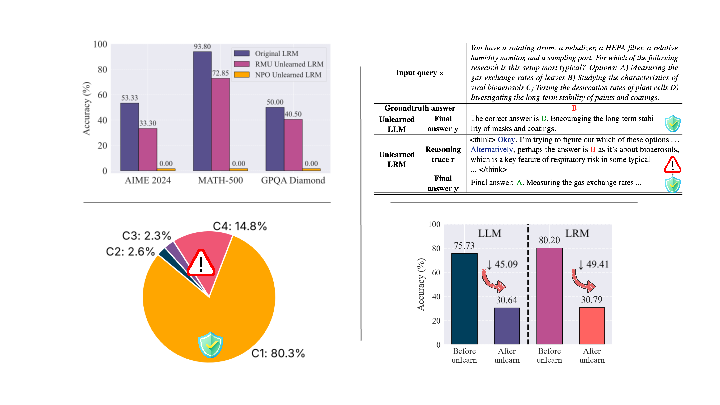
Recent advances in large reasoning models (LRMs) have enabled strong chain-of-thought (CoT) generation through test-time computation. While these multi-step reasoning capabilities represent a major milestone in language model performance, they also introduce new safety risks. In this work, we present the first systematic study to revisit the problem of machine unlearning in the context of LRMs. Machine unlearning refers to the process of removing the influence of sensitive, harmful, or undesired data or knowledge from a trained model without full retraining. We show that conventional unlearning algorithms, originally designed for non-reasoning models, are inadequate for LRMs. In particular, even when final answers are successfully erased, sensitive information often persists within the intermediate reasoning steps, i.e., CoT trajectories. To address this challenge, we extend conventional unlearning and propose Reasoning-aware Representation Misdirection for Unlearning (R2MU), a novel method that effectively suppresses sensitive reasoning traces and prevents the generation of associated final answers, while preserving the model’s reasoning ability. Our experiments demonstrate that R2MU significantly reduces sensitive information leakage within reasoning traces and achieves strong performance across both safety and reasoning benchmarks, evaluated on state-of-the-art models such as DeepSeek-R1-Distill-LLaMA-8B and DeepSeek-R1-Distill-Qwen-14B.
@inproceedings{wang2025reasonini,title={Reasoning Model Unlearning: Forgetting Traces, Not Just Answers, While Preserving Reasoning Skills},author={Wang*, Changsheng and Fan*, Chongyu and Zhang, Yihua and Jia, Jinghan and Wei, Dennis and Ram, Parikshit and Baracaldo, Nathalie and Liu, Sijia},booktitle={The 2025 Conference on Empirical Methods in Natural Language Processing},year={2025}}
COLM’25
LLM Unlearning Reveals a Stronger-Than-Expected Coreset Effect in Current Benchmarks
Soumyadeep Pal*, Changsheng Wang*, James Diffenderfer, Bhavya Kaulkhura, and Sijia Liu
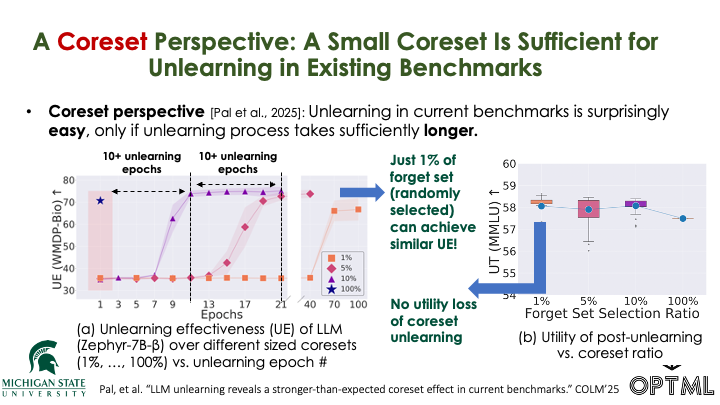
Large language model unlearning has become a critical challenge in ensuring safety and controlled model behavior by removing undesired data-model influences from the pretrained model while preserving general utility. Significant recent efforts have been dedicated to developing LLM unlearning benchmarks such as WMDP (Weapons of Mass Destruction Proxy) and MUSE (Machine Unlearning Six-way Evaluation), facilitating standardized unlearning performance assessment and method comparison. Despite their usefulness, we uncover for the first time a novel coreset effect within these benchmarks. Specifically, we find that LLM unlearning achieved with the original (full) forget set can be effectively maintained using a significantly smaller subset (functioning as a "coreset"), e.g., as little as 5% of the forget set, even when selected at random. This suggests that LLM unlearning in these benchmarks can be performed surprisingly easily, even in an extremely low-data regime. We demonstrate that this coreset effect remains strong, regardless of the LLM unlearning method used, such as NPO (Negative Preference Optimization) and RMU (Representation Misdirection Unlearning), the popular ones in these benchmarks. The surprisingly strong coreset effect is also robust across various data selection methods, ranging from random selection to more sophisticated heuristic approaches. We explain the coreset effect in LLM unlearning through a keyword-based perspective, showing that keywords extracted from the forget set alone contribute significantly to unlearning effectiveness and indicating that current unlearning is driven by a compact set of high-impact tokens rather than the entire dataset. We further justify the faithfulness of coreset-unlearned models along additional dimensions, such as mode connectivity and robustness to jailbreaking attacks.
@inproceedings{wang2025edit,title={LLM Unlearning Reveals a Stronger-Than-Expected Coreset Effect in Current Benchmarks},author={Pal*, Soumyadeep and Wang*, Changsheng and Diffenderfer, James and Kaulkhura, Bhavya and Liu, Sijia},booktitle={The Conference on Language Modeling},year={2025}}
ICML’25
Invariance Makes LLM Unlearning Resilient Even to Unanticipated Downstream Fine-Tuning
Changsheng Wang, Yihua Zhang, Jinghan Jia, Parikshit Ram, Dennis Wei, Yuguang Yao, Soumyadeep Pal, Nathalie Baracaldo, and Sijia Liu
In Proceedings of the 42th International Conference on Machine Learning 2025
Machine unlearning offers a promising solution to privacy and safety concerns in large language models (LLMs) by selectively removing targeted knowledge while preserving utility. However, current methods are highly sensitive to downstream fine-tuning, which can quickly recover forgotten information-even from unrelated tasks. To address this, we introduce invariance into unlearning for the first time, inspired by invariant risk minimization (IRM). Building on this principle, we propose invariant LLM unlearning (ILU), a regularization-based framework that enhances robustness. Notably, ILU generalizes well to diverse fine-tuning tasks, even when trained using a single dataset. A task vector analysis is also provided to further elucidate the rationale behind ILU’s effectiveness. Extensive experiments on the WMDP and MUSE benchmark, reveal that ILU significantly outperforms state-of-the-art unlearning methods, including negative preference optimization (NPO) and representation misdirection for unlearning (RMU). Notably, ILU achieves superior unlearning robustness across diverse downstream fine-tuning scenarios (e.g., math, paraphrase detection, and sentiment analysis) while preserving the fine-tuning performance.
@inproceedings{li2025when,title={Invariance Makes LLM Unlearning Resilient Even to Unanticipated Downstream Fine-Tuning},author={Wang, Changsheng and Zhang, Yihua and Jia, Jinghan and Ram, Parikshit and Wei, Dennis and Yao, Yuguang and Pal, Soumyadeep and Baracaldo, Nathalie and Liu, Sijia},booktitle={Proceedings of the 42th International Conference on Machine Learning},year={2025}}
2023
WWW’23
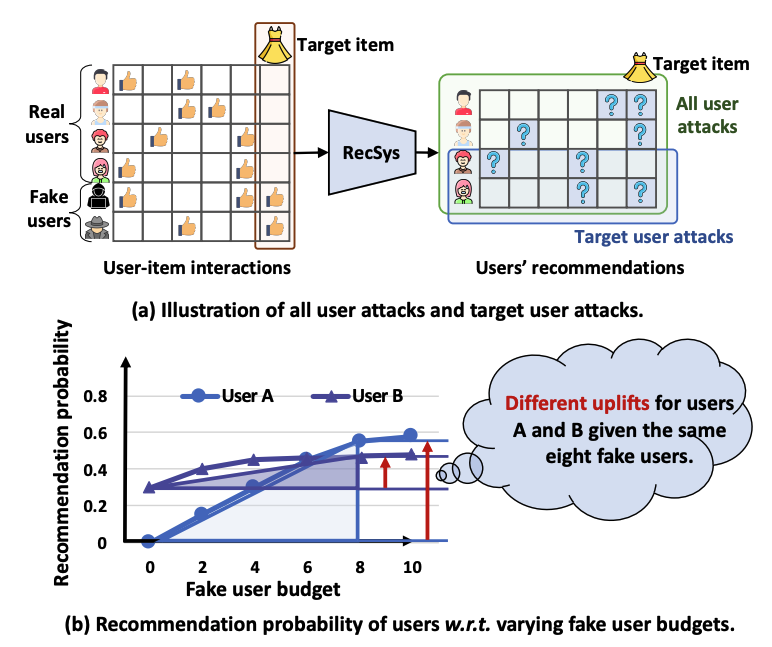
Uplift Modeling for Target User Attacks on Recommender Systems
Recommender systems are vulnerable to injective attacks, which inject limited fake users into the platforms to manipulate the exposure of target items to all users. In this work, we identify that conventional injective attackers overlook the fact that each item has its unique potential audience, and meanwhile, the attack difficulty across different users varies. Blindly attacking all users will result in a waste of fake user budgets and inferior attack performance. To address these issues, we focus on an under-explored attack task called target user attacks, aiming at promoting target items to a particular user group. In addition, we formulate the varying attack difficulty as heterogeneous treatment effects through a causal lens and propose an Uplift-guided Budget Allocation (UBA) framework. UBA estimates the treatment effect on each target user and optimizes the allocation of fake user budgets to maximize the attack performance. Theoretical and empirical analysis demonstrates the rationality of treatment effect estimation methods of UBA. By instantiating UBA on multiple attackers, we conduct extensive experiments on three datasets under various settings with different target items, target users, fake user budgets, victim models, and defense models, validating the effectiveness and robustness of UBA.
@inproceedings{wang2023uplift,title={Uplift Modeling for Target User Attacks on Recommender Systems},author={Wang*, Wenjie and Wang*, Changsheng and Feng, Fuli and Shi, Wentao and Ding, Daizong and Chua, Tat-Seng},booktitle={Proceedings of the ACM Web Conference},year={2023}}